


Entendendo o GloVe: Uma Jornada pelo Espaço Vetorial das Palavras
Ao longo do texto, discutimos passo a passo um meio elegante e moderno para entender como a linguagem humana pode ser representada matematicamente em um computador.


Lidar com textos no aprendizado de máquina costuma ser complicado. Isso em parte acontece pelo fato de computadores apenas lidarem com números. Mesmo este texto que você está lendo agora está codificado em UTF-8, um formato comum para representar caracteres que permite mostrar uma grande variedade de símbolos e letras em formato digital.
Quando falamos de algoritmos de aprendizado de máquina, outro problema surge: esses algoritmos precisam processar números para que possam extrair padrões e estabelecer regras para a tomada de decisões. Para que isso seja feito, é necessário representar os textos de alguma maneira útil para estes algoritmos. Nisso, estamos discutindo o conceito de representação de palavras, ou word embedding.
Muitas técnicas de word embedding foram propostas ao longo das décadas. Por exemplo, a técnica Bag-of-Words, uma maneira simples de representar palavras, tem sido amplamente usada desde os primórdios da IA [1]. Dessa forma, reforço que existem muitas maneiras de se fazer word embedding e que existe um longo histórico nisso. No entanto, vamos direcionar a atenção ao GloVe, que é o objetivo principal deste texto.
Relembrando o Word2Vec para entender o GloVe
É limitante entender o GloVe sem mencionar abordagens anteriores. Muito do que existe de mais moderno em PLN1 é consequência de superar limitações do que veio antes. Assim sendo, vamos relembrar um pouquinho do Word2Vec e seu papel ao inspirar o GloVe.
O Word2Vec é um modelo de aprendizado de máquina, especificamente uma rede neural artificial2, que “transforma” palavras em vetores numéricos. A ideia é simples, porém engenhosa: treinar uma rede neural para prever a palavra com mais probabilidade de aparecer em um texto e pegar os vetores que representam palavras que surgiram neste processo.
Ok, isso pode ser difícil de entender, então vamos recorrer a um exemplo didático.
Imagine que nosso conjunto de treinamento é composto pela frase “O cachorro come ração”. Nisso, precisamos de uma janela de contexto, que nada mais é uma janela deslizante, que “anda” por partes do texto, analisando palavras próximas.
Assim, se a janela tiver tamanho 2, os pares analisados são:
“O”, “cachorro”
“cachorro”, “come”
“come”, ”ração”
No entanto, convém dizer que o exemplo acima é bastante simplificado. Na verdade, os pares analisados sempre consideram uma palavra central, que vou destacar em itálico, e palavras de contexto:
Para “o”:
“O”, “cachorro”
Para “cachorro”:
“O”, “cachorro”
“cachorro”, “come”
Para “come”:
“cachorro”, “come”
“come”, “ração”
Para “ração”:
“come”, “ração”
Pode parecer redundante analisar pares repetidos, mas é importante observar que a palavra central e as de contexto mudam durante o “caminhar” da janela. Isso permite capturar nuances de cada termo em contextos diferentes, deixando o aprendizado mais rico.
Certo, e o que ocorre durante essa passagem de janela?
A ideia é treinar uma rede neural para prever qual seria a palavra de contexto que teria mais probabilidade de aparecer, considerando as frases usadas no treinamento.
Como tipicamente acontece em treinamentos envolvendo redes neurais, cada palavra é representada por um vetor de muitas dimensões, inicializado por números aleatórios. Por exemplo, “cachorro” poderia ser o vetor [0,2, -0,1, 0,5, …, 0,3] e “come”, por sua vez, poderia ser o vetor [0,4, 0,9, -0,5, …, -0,2].
O treinamento da rede neural pode ser feito da seguinte maneira: para cada par, a palavra central é usada para prever as palavras de contexto3. Por exemplo, a partir de “cachorro”, se tentaria estimar os termos que costumam aparecer juntos, tais como “o” e “come”.
Mais especificamente, a ideia é calcular probabilidades para todas as palavras do vocabulário, de maneira que os valores mais altos indicam termos com mais probabilidade de aparecerem próximos da palavra central.
Isso é feito utilizando técnicas comuns no treinamento de redes neurais, como a função de perda de entropia cruzada (cross-entropy) e o método do gradiente. Não vou falar muito sobre para não desviar o foco. No entanto, isso é feito para ajustar os vetores de palavras, como se fosse um problema de classificação: dada uma palavra central, são selecionadas as que têm maior probabilidade de serem termos do contexto, considerando o vocabulário inteiro. Inclusive, usa-se a função softmax para isso.
Na realidade, o problema de classificação usado para “prever” as palavras que coocorrem é um meio para um fim maior. O que queremos é o subproduto de tudo isso: os vetores numéricos que definem cada termo unicamente.
Ao final desse processo, os termos com significados e usos semelhantes tendem a ter vetores com valores parecidos e, consequentemente, estarem “próximos” num espaço vetorial. Na imagem abaixo, por exemplo, formam-se pequenos grupos de palavras relacionadas, desde nomes de pessoas no topo superior direito e de áreas de conhecimento no canto inferior direito.

Dessa forma, esses vetores acabam sendo representações matemáticas de palavras conhecidas, e que podem ser usadas para tarefas diversas em PLN, tais como análise de sentimento e classificação de texto (no meu canal, eu fiz um vídeo usando essa estratégia para classificar se notícias de futebol são de clubes como Flamengo, Corinthians e afins).
Ok, Lucas, se o Word2Vec é tão bom assim, posso usar ele e não preciso de mais nada, né?
Não é bem assim. Uma das limitações do Word2Vec é a sua natureza profundamente local. Seu método de treinamento é baseado no contexto das palavras próximas (por conta das janelas que mencionamos antes). Nisso, perde-se a relação global entre palavras que não necessariamente aparecem juntas em textos, mas que compartilham significados semelhantes.
Por conta disso, convém falarmos de abordagens globais. Uma das mais conhecidas baseia-se em Análise Semântica Latente (Latent Semantic Analysis), que também produz vetores numéricos que representam palavras, mas usando uma análise estatística global para essa tomada de decisão.
Novamente, vamos usar um exemplo didático para explicar essa abordagem. Dessa vez, vamos imaginar que nosso conjunto de documentos (corpus) consta de quatro frases:
“O gato come peixe.”
“O cachorro come ração.”
“O gato brinca com a bola.”
“O cachorro brinca no jardim.”
O primeiro passo consiste em construir uma matriz de coocorrência, que nada mais é uma tabela em que cada linha e coluna representam as palavras que aparecem nas frases. Sempre que duas palavras aparecem próximas (se a janela tiver tamanho 2), isso faz com que seja somado 1 nessa posição. Para entender, considere a matriz de coocorrência das quatro frases acima:
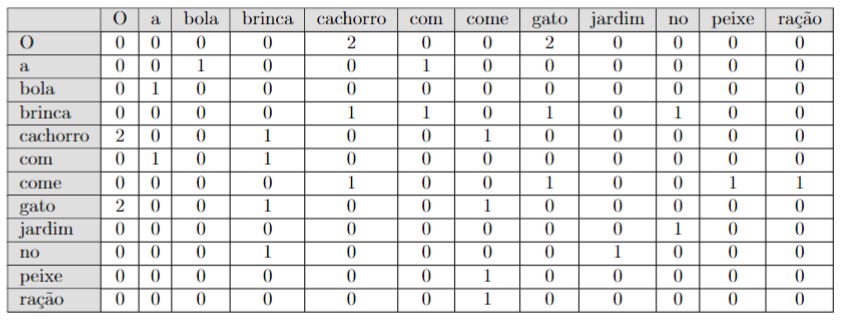
Note que, na tabela acima, a primeira linha é referente ao “O”. Na linha “O” e coluna “cachorro”, temos o número 2. Isso acontece pois, no conjunto de frases, a expressão “O cachorro” ocorre duas vezes. Já na linha “gato” e coluna “brinca”, temos 1, pois só existe uma situação em que ocorre “gato brinca”. E na linha “gato” e coluna “cachorro” temos 0, pois não há uma única situação em que as palavras “gato cachorro” aparecem juntas.
A seguir, aplicamos uma estratégia chamada Decomposição em Valores Singulares (Singular Value Decomposition - SVD)4. Explicando de maneira didática, é como se “compactássemos” a informação original da matriz de coocorrência, “jogando fora” algumas informações menos relevantes, como a quantidade enorme de zeros da matriz original.
Não vou entrar em detalhes sobre o funcionamento do SVD, pois isso daria um texto a parte. No entanto, é uma maneira bem conhecida de reduzir a dimensionalidade dos dados, ou seja, representar o máximo que for possível da matriz original, só que usando menos linhas e colunas. É um método que compartilha muitas similaridades com o PCA, se você já tiver ouvido falar ou usado em algum momento. Já fiz vídeo sobre PCA, inclusive.
Após aplicar o SVD, a matriz original é decomposta em 3 outras matrizes: U, S e Vt. Explicando intuitivamente, é como se a matriz U representasse os termos (em cada linha) e os “conceitos abstratos” descobertos da matriz original que relacionam as palavras (em cada coluna). Assim, uma coluna pode representar um “universo de carros” e, assim, termos relacionados a esse tema, como “motor” e “rodar” teriam valores mais altos, indicando que são importantes para este conceito. Além disso, termos semanticamente próximos ou frequentemente usados juntos podem ter valores numéricos próximos também.
De maneira similar ao U, a matriz Vt também representa “conceitos abstratos”, como se fossem um campo de conhecimento. No entanto, ao invés de associar essas ideias a termos, ele faz isso entre documentos. Assim como cada coluna de U, as linhas de Vt representam essas “ideias abstratas”. Aqui, cada coluna de Vt é um documento, que pode representar uma frase, texto ou notícia em particular, dependendo do contexto. Seguindo a analogia anterior, cada coluna é como se fosse uma amostra de texto que usamos no aprendizado e vamos associar a um conceito, como “universo de carros”.
Finalmente, S é uma matriz diagonal (ou seja, todos os elementos fora da diagonal principal são zero) e estes indicam a “importância” ou “peso” dos “conceitos abstratos” descobertos nas matrizes U e Vt.
Abaixo, temos um exemplo de possíveis matrizes U, S e Vt geradas pela matriz de coocorrências mencionada anteriormente.

Essas matrizes possuem dimensão 12x12, pois foram construídas a partir de 12 palavras, das 4 frases didáticas que mostramos antes. Cada linha de U representa uma palavra e suas colunas associam-se a “conceitos abstratos”. Uma possível coluna, por exemplo, pode representar termos relacionados ao “universo de animais”, fazendo com que “gato” e “cachorro” tenham valores mais altos nessa coluna. Matematicamente essas colunas surgem da combinação linear entre os termos específicos.
A matriz Vt costuma relacionar documentos em cada coluna (que no contexto são as frases, como “O gato come peixe.” e “O cachorro come ração.”, dentre outras). As linhas referem-se aos mesmos “conceitos abstratos” das colunas de U.
Nisso, pode surgir uma questão: se a matriz de coocorrência foi gerada a partir de 4 frases, como podem existir 12 colunas?
Isso ocorre pois o número de termos acaba ditando a dimensão das matrizes do SVD. As 4 primeiras colunas refletem a relação das frases com os “conceitos abstratos”. As demais linhas provavelmente estão capturando detalhes redundantes ou não essenciais.
Finalmente, o S diz para cada valor diagonal, qual a importância dos conceitos abstratos. Quanto mais você “desce” nessa diagonal, menores são os valores. A diagonal para o exemplo que estamos desenvolvendo, inclusive, é essa abaixo.
[3.713, 3.525, 1.734, 1.695, 1.301, 1.231, 1.214, 0.925, 0.43,
0.425, 0. , 0. ]Essa diagonal acaba servindo como referência, pois ela nos ajudará a definir a dimensionalidade dos vetores que representam palavras. Essa é uma informação que nós escolhemos.
Considerando que os dois primeiros valores são bem maiores do que o restante, faz sentido optar por vetores 2D para representar as palavras. No entanto, isso pode ocasionar perda de informação, pois com dimensionalidade maior, podemos capturar mais nuances. No fim, essa escolha não é simples, pois é preciso achar um meio termo entre uma boa captura de informações e o custo computacional de lidar com vetores grandes. Testar para vários casos acaba sendo importante também, para observar o que funciona melhor na prática.
Enfim, supondo que façamos essa escolha por duas dimensões, o que fazemos agora? É simples: multiplicamos a matriz U reduzida (o mesmo U, só que mantendo apenas as 2 primeiras colunas) pelo S reduzido (apenas 2 linhas e 2 colunas do S original). Descartamos Vt pois essa matriz só seria útil se quiséssemos fazer uma análise no nível de frases ou documentos, por exemplo, para classificar se uma notícia é do caderno de esportes, política, cultura, etc. A matriz U captura a semântica dos termos especificamente, que é o que nos interessa quando trabalhamos com word embeddings. Assim, o Vt não é útil para o que estamos fazendo e usá-lo pode nos obrigar a fazer mais cálculos do que precisa.
Ao final, temos os seguintes vetores representando cada palavra:
O: [2.72578, 0.00000]
a: [0.15237, 0.00000]
bola: [0.00000, -0.04262]
brinca: [1.64277, 0.00000]
cachorro: [0.00000, -2.43627]
com: [0.00000, -0.50211]
come: [1.61570, 0.00000]
gato: [0.00000, -2.43627]
jardim: [0.13943, 0.00000]
no: [0.00000, -0.49850]
peixe: [0.00000, -0.45193]
ração: [0.00000, -0.45193]
Muito bem Lucas, só que você está há um tempão falando de outros métodos e nada de GloVe!
Eu fiz isso por um motivo: o GloVe surgiu como uma resposta às limitações dos métodos anteriores.
O Word2Vec é uma abordagem local, baseada no aprendizado de palavras muito próximas e orientada pelas janelas deslizantes. Com isso, informações globais, baseadas na relação de palavras em textos como um todo é desconsiderada.
Na abordagem com SVD, como na Análise Semântica Latente, ocorre o oposto: ela utiliza uma estatística global (a matriz de coocorrência) e reduz sua dimensionalidade. Ela considera a frequência total de palavras ocorrendo juntas e perde a captura de relações locais finas envolvendo semântica e sintaxe, algo que tínhamos com o Word2Vec.
Assim, um pensamento óbvio surgiu entre seus autores: e se criássemos um modelo que combina a extração de informações local e global, incorporando ambas ao algoritmo? Basicamente esse é o GloVe, ou Global Vectors for Word Representation.
Para fechar, vamos explicar como o GloVe funciona com um exemplo simples. Vamos imaginar um corpus de texto bastante simples, contendo 3 frases:
"Gato gosta de peixe."
"Cachorro gosta de osso."
"Gato e cachorro são animais."
Novamente, vamos construir uma matriz de coocorrência para as frases acima.

Feito isso, inicializamos os vetores que representam cada uma das 9 palavras com valores aleatórios e que serão obtidos mediante treinamento e otimização para a função de custo abaixo.
Não se desanime com a fórmula acima! Vou tentar explicar cada um dos parâmetros de maneira didática.
A ideia é minimizar a função de custo total J.
Para isso, realizamos o somatório de todos os pares de palavras vi e vj de todos o vocabulário V.
Xij é o número de vezes em que a palavra i ocorre no contexto de j. Por exemplo, se a palavra i for “de” e o termo j for “gosta”, o Xij desse caso é 2. Isso ocorre pois “de” aparece na vizinhança de “gosta” 2 vezes, como é possível ver na matriz.
f(Xij) é uma função de ponderação, que evita dar importância às coocorrências muito frequentes. Isso é para evitar que termos que coocorrem com muita frequência, como “de”, “e”, “o” e “a” dominem a análise.
Os termos vi, vj, bi e bj são os vetores de palavras e termos de viés para i e j. Eles são ajustados de maneira análoga ao que ocorrem com redes neurais, em que o treinamento vai fazer com que os melhores valores sejam atribuídos para eles.
Agora vamos focar nossa atenção no logaritmo, que é crucial e serve de base para o ajuste dos vetores de palavras.
Assim como a função de ponderação, o logaritmo procura ajustar a escala de frequência das coocorrências. Assim, termos comuns que aparecem com frequência junto a outras palavras tendem a ter um “teto” ajustado, sem crescer demasiadamente. Isso ajuda a reduzir o impacto de discrepâncias extremas e ressaltar relações que não são muito comuns e que carregam informações semânticas relevantes.
Ao multiplicar vi e vj, estamos medindo a similaridade entre as palavras i e j (já que estamos falando do produto interno entre estes vetores). Como o objetivo é minimizar J, queremos descobrir vetores vi e vj que, ao subtrairmos pelo logaritmo, nos aproximamos de 0. Isso significa que, quanto mais frequentemente duas palavras coocorrem, mais próximo será o seu produto escalar do logaritmo dessa frequência.
Releia a frase anterior mais de uma vez, pois ela é importante.
Isso cria uma relação direta entre a similaridade dos vetores de palavras e a frequência de coocorrência das frases, integrando análises estatísticas e representações vetoriais. Com isso, consideramos a sintaxe e a semântica do local e global ao mesmo tempo.
A subtração em questão é uma maneira de fazer com que os vetores que representam as palavras não só capturem relações semânticas e sintáticas, mas também reflitam as coocorrência observadas nas frases. Ao fazer isso, o GloVe consegue produzir vetores de palavras que são tanto semanticamente ricos quanto estatisticamente fundamentados.
Antes de ir embora…
Espero que essa explicação tenha te ajudado a entender! Se você gosta do meu conteúdo, me ajude a produzir cada vez mais enviando uma contribuição no pix: universodiscretopix@gmail.com 💰.
Não deixe de visitar o youtube.com/universodiscreto para ver os conteúdos que tenho produzido em vídeo. Para saber tudo que produzo na internet, acesse linktr.ee/universodiscreto. Muito obrigado!
Saiba mais
Grande parte do que escrevi no texto, usou a aula abaixo de Stanford como base. O ChatGPT também ajudou muito a formular exemplos e revisar o texto como um todo.
Referências
[1] https://www.tandfonline.com/doi/abs/10.1080/00437956.1954.11659520
[2] https://sol.sbc.org.br/index.php/ctic/article/view/10013
[3] https://nlp.stanford.edu/projects/glove/
Processamento de linguagem natural é um campo de pesquisa que investiga e propõe métodos para lidar com o processamento computacional da linguagem humana. Para entender mais sobre, eu recomendo esse livro: https://brasileiraspln.com/livro-pln/1a-edicao/.
Se você deseja entender mais sobre redes neurais artificiais de maneira geral, eu recomendo esse texto: https://universodiscreto.substack.com/p/o-que-as-redes-neurais-fazem-exatamente-para-aprender
Essa não é a única forma de se trabalhar com Word2Vec. Para fins didáticos, foquei na abordagem Skip-gram, que é a descrita no texto. Entretanto, existe a variante CBOW (Continuous Bag-of-Words), que faz o oposto: tenta estimar a palavra central a partir das palavras de contexto.
Em geral não é a melhor opção aplicar a matriz de coocorrências diretamente, mas fiz isso aqui para manter um pouco de simplicidade no texto.